
- Published on
Week 39 in review
- Authors

- Name
- Edwin Groenendaal
- @dharmatologist
This week we list some of the highlights of our monthly Labs presentation, and talk about the challenge of building flexible, yet reliable APIs.

What's happened this week?
This week the Labs the team presented their latest work to the Board. They do this monthly, and each session is a combination of data-science 'fireworks' and Q/A about product potential. It's a great opportunity for the Board to get directly involved.
So for this post we thought we'd highlight some of the work that we showcased in Thursday's presentation.
ADDRESSABLE
PDFx extractions inside the ADDRESSABLE knowledge graph
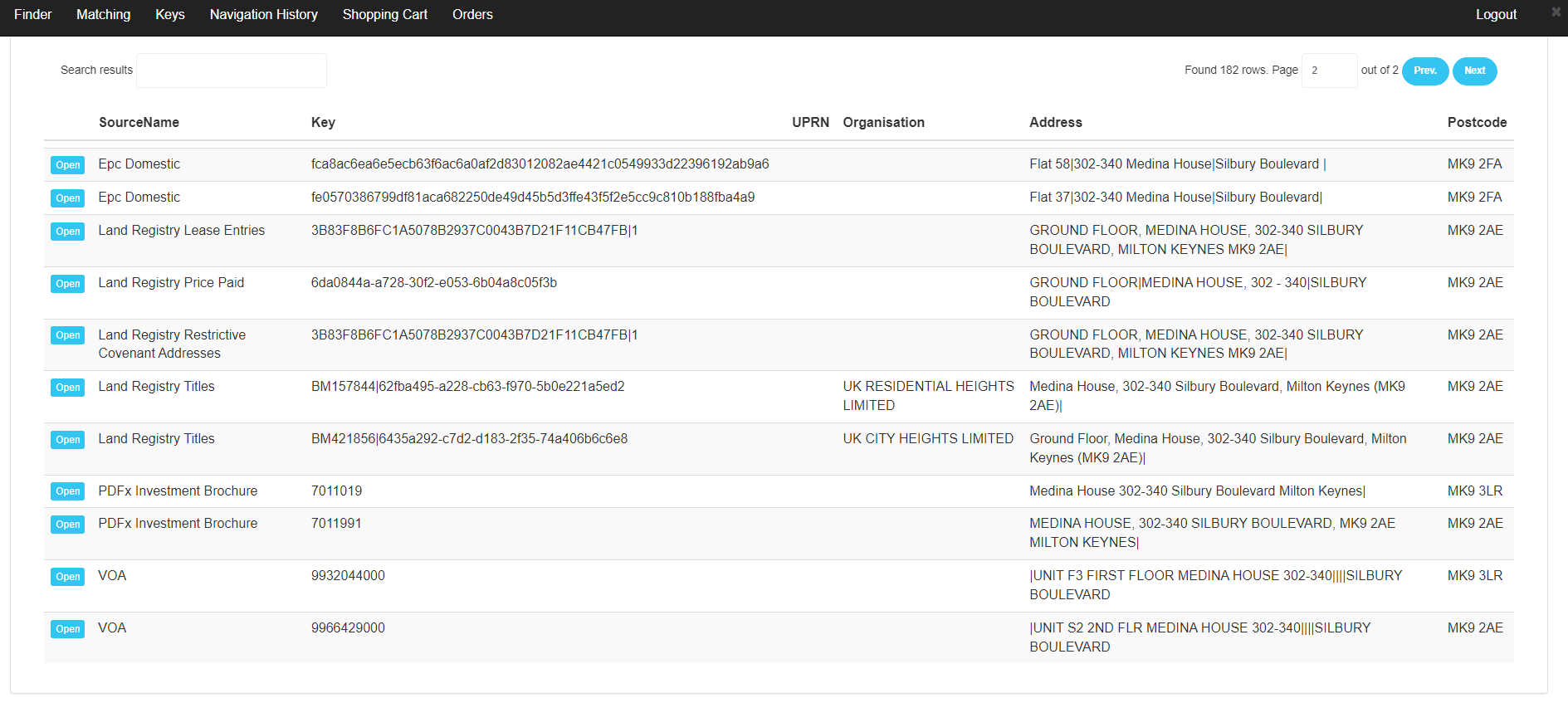
To test our new schema-less data ingestion capabilties (see below), we ingested some PDFx extraction results into ADDRESSABLE. We have an internal test and training set of PDFs and we imported some 10,000 of these into our knowledge graph.
They slot in nicely, and you can see in the screenshot that "PDFx investment brochure" is now a new entity type, one of several new PDFx-related nodes in the knowledge graph.
Although still in 'lab' stage, we think this is very promising and we'll work on a schedule for QA and a production roll-out. Long-term, we'd like to offer ADDRESSABLE access to some of our PDFx users, allowing them to query their extracted results using a personalised instance.
And for us, importing our training set into ADDRESSABLE gives us an unprecedented ability to correlate extraction performance against any attribute in the data universe.
Ingesting user data
The PDFx data is a trial run for an upcoming feature - the ability to upload your own data into ADDRESSABLE. Traditionally, ingesting user data means offering some form of data transformation or data mapping interface, where users map columns (in a spreadsheet) to data points in the data warehouse. A manual and painful exercise, that only works on the fixed-format data sets common in legacy systems.
Today's data stores are flexible, with rapid schema changes or schema-less documents. Having to map data fields every time you update a data set means manual error-prone work, and that means you simply won't want to do it very often.
So with ADDRESSABLE, our view is to offer automatic classification where possible. This means users will drop in their data, and we'll classify fields automatically based on content or context. We've already built the know-how into PDFX (after all, that's how data extraction works) and we plan to apply this to ADDRESSABLE.
This includes the ability to recognise addresses and companies, and automatically insert uploaded data into the relevant address or business record.
Visualising JSON data
Currently we're focussing on ingesting JSON data, because it's a common format and it allows for schema-less data expression. We have applied our 'meta' User Interface to JSON data, and we now support automatic creation of detail screens for JSON documents. We support basic types (text, numbers, etc.) as well as nested (tabular) data.
Below are some screenshots of a JSON document, ingested into ADDRESSABLE and visualised automatically.
We see great potential in automatic classification and joining-up of data, because mapping and joining are huge bottlenecks in existing data collection systems.
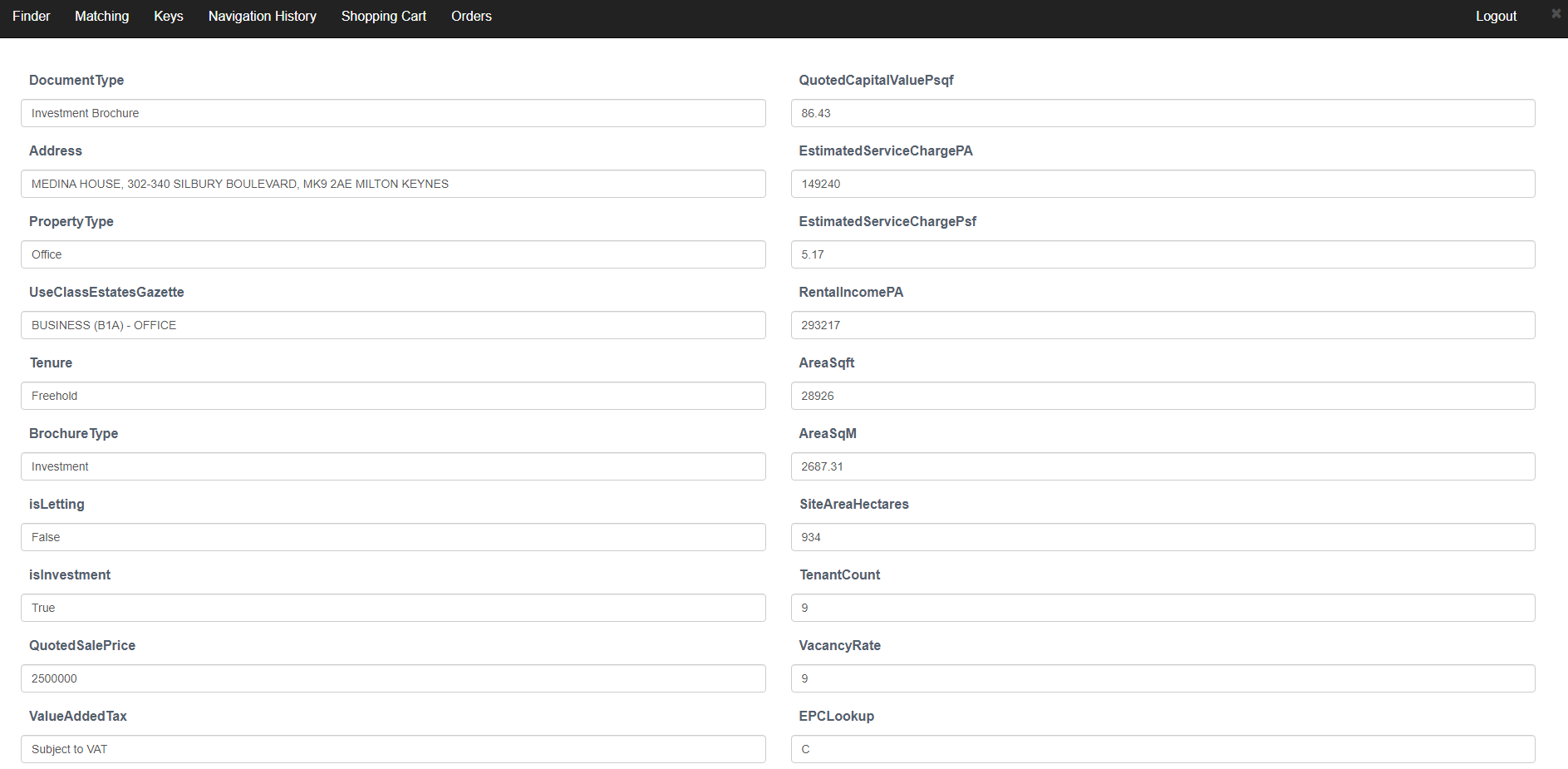
Screenshot - A JSON document in ADDRESSABLE
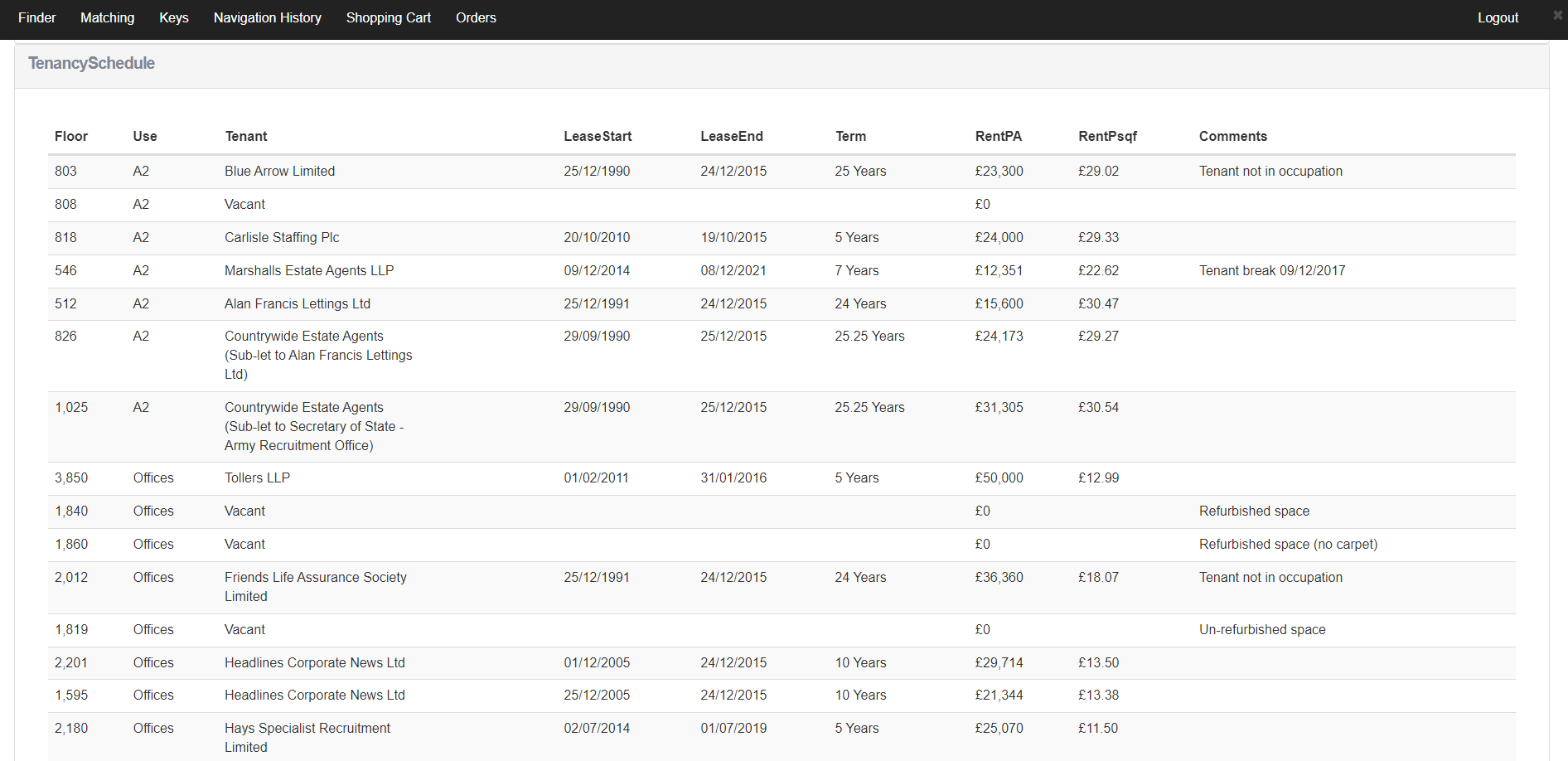
Screenshot - A table inside a JSON document, visualised in ADDRESSABLE
PDFx
Flexible can be reliable
We continue to work on the current, mainline version of PDFx - adding features, squashing bugs, the usual - and we're quietly planning the next iteration of the PDFx UI and API.
We are building a beautiful new API layer that lets us make changes to the core extraction, ship them to clients fast, and still offer a reliable and dependable set of APIs. More importantly, we will put the power of versioning in the hands of our operations team, and remove the need of engineering to get involved all the time. Flexible, fast to roll out, and yet dependable.
What's the big deal?
When working on a tool like PDFx, where the volume and variation of data exposed (extracted, in this case) keeps changing, you have to balance the need to move fast (we move very fast) and the need to deliver a reliable and dependable service:
When new data points are added or retired, and changes to the extraction tech are integrated, you want to make those available to the user interface and the API, so you can run internal tests, expose new features to early adopters, and roll out speedily. Software Engineers know how to make this happen - flexible 'property bag' structures allow you to serialise flexible sets of data, and there is little to no coding required to accommodate changes.
But on the other hand, you want a dependable API with predictable outcomes, that has checks built in to ensure mistakes don't automatically propagate across the system and make their way to clients. Developers know how to design and implement dependable APIs. Strongly typed languages like Java and Go reduce run-time issues and allow fixed-format outputs.
The issue is, these are mutually exclusive approaches. Either you pick a flexible format for speed and agility, or you build a static format that traps mistakes at design-time. Pick flexible, and you run the risk of shipping undesired behaviour to clients. Pick static, and you will be slowed down by the need to make code changes every time your data schema changes.
Adding managed configuration
For the next version of PDFx, we will add a management layer that encapsulates an API version. Basically, a list of fields that are exposed by the API, in a nested structure, with data types, display meta-data, and so on.
This allows us to validate extracted data points, convert or format values, and design response structures that we think are appropriate. All using a configuration interface that the ops team will manage. In fact, they will manage the life-cycle of API versions, without the need for Engineering to be involved.
This means we can rapidly expose extraction changes to our internal testing and training teams, and roll out new extractions to clients quickly, with full control of data types, formatting, and API version integrity.
Pretty cool!
Interested in finding out more? Contact us →