
- Published on
Week 36 in review
- Authors

- Name
- James Wilson
- @jwilson92
Data means nothing without accuracy. Or that's our thinking at least. Last week, we finalised our planning session with the goal that this final QTR should be spent on developing features that empower users, increasing confidence that the data provided / extracted is accurate and as such is valuable.
We all make mistakes, but having a system in place which highlights / identifies potential outliers early is a critical part in building confidence.

What's been worked on
PDFx
Underwriting - as a capability
Last week we briefly touched on a new document type being trained within the PDFx extraction algorithms. This document type is for Insurance Underwriting purposes. Coupled with Addressable the client has been given a proof of concept and is trailing the capabilities to enhance their underwriting workflow within PDFx to ensure that the triage of policies is no longer such a time consuming project.
Enhanced reporting
At present PDFx does not have an admin dashboard for clients. This will change in the near future based on our previous mockups and planning sessions, but for the time being we are implementing better reporting (via e-mail) to ensure that account administrators have visiblity on productivity and the pipeline of processed documents. Whilst this is only a 'stop-gap' we appreciate the requirement of transparency and so will continue to complete ad-hoc works until the first build of the admin dashboard has been completed.
Canary
The sneak peek of the OCR capabilities last night seemed to be well received! This week we're happy to extend this sneak peek even further by showing how this will work with the updated table functionality.
Addressable
Data Analysis
Whilst most of the Addressable team are on vacation we have tasked our Junior Data scientist with examining the data and compiling a number of 'stories' which can be told via the data. We hope to release on the main homepage in the coming weeks but for the time being, enjoy these visualisations!
Releases
PDFx
This week we released our updated version of PDFx (Both the User Interface and also the extraction algorithms).
UI
- Folders
- Allowing users to create their own folder hierarchy within the application. Whilst it may seem like a simple improvement, in user trials it further improved efficiency for assigning and reviewing documents as they landed in particular, user set folders.
- Improved Coordinates
- Following on the theme of accuracy being key, for datapoints that need reviewing, PDFx now shows a more accurate location of the extraction either on the dot or at the beginning of the line.
- Clickable features
- Clients are finding the features being extracted from a document increasingly valuable when analysing the data. To help improve confidence and transparency in the extraction we have made features clickable, showing you exactly where in the document the feature was found.
Algorithm
- Client algorithm updates
- Based on the documents processed since the last update all clients will now have received an update to the algorithm used when extracting documents within their workspace. The update will only apply to documents processed from this date forward.
- Increased table accuracy
- Increased accuracy for column mapping across Tenancy and Investment comparables predominantly.
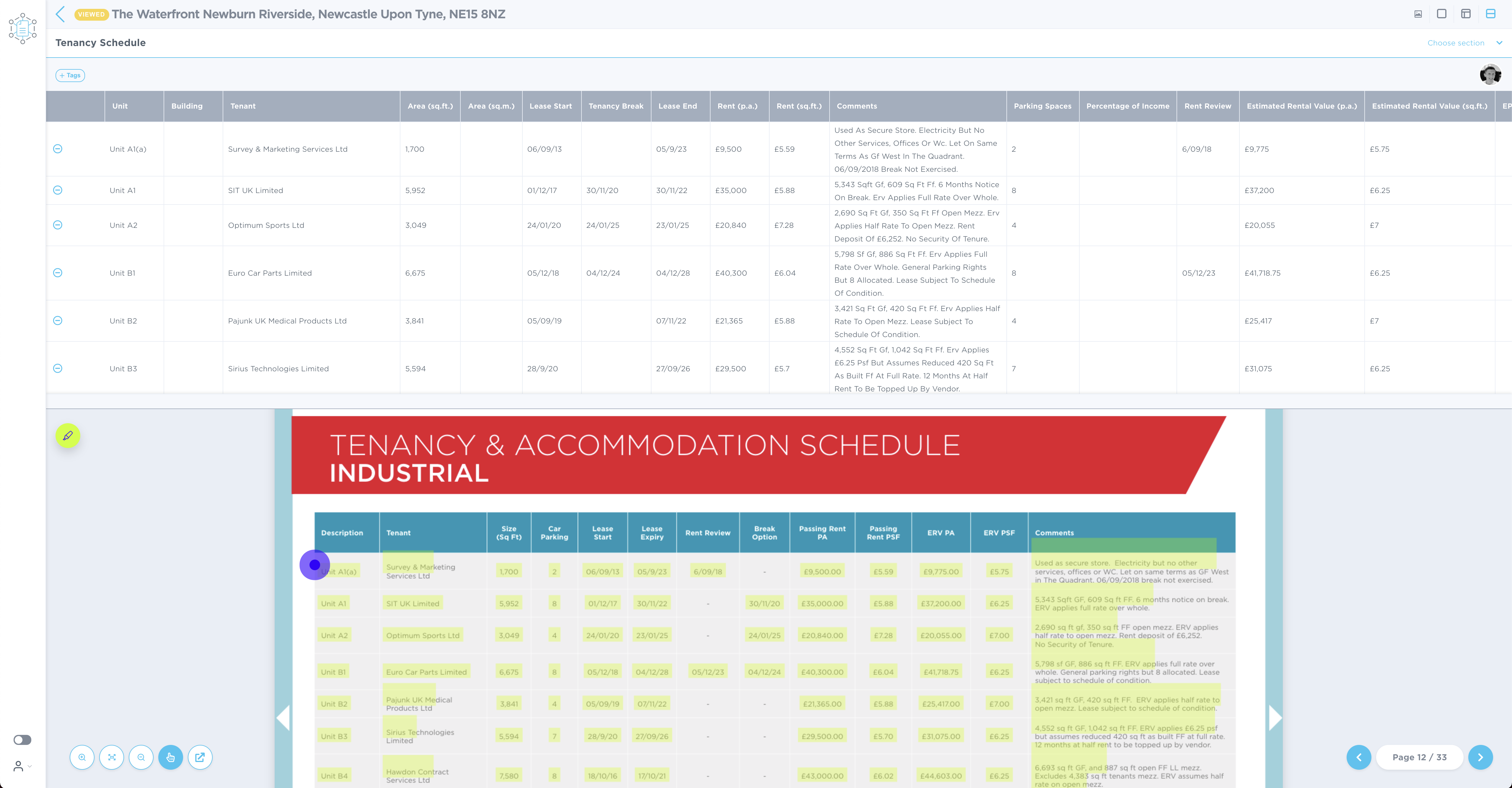
To empower users we are also working on an updated design for showing the data that has been extracted. The table will aims to be clearer and allow excel like functionality for that crisp editing feeling.
What's coming up
PDFx
In order to improve confidence in the data we will be creating a new feature within the application itself which will utilise the data extracted from the rest of the document to highlight any potential inaccuracies. This may be validating the summary Area Sq Ft with the Acommodation table or the tenant count with the Tenancy schedule from Investment Brochures. Whilst this will be a highly complicated task we will also need to ensure that the process times for documents are not improvised.
We take great pride in the data that PDFx extracts - and how quickly it's structured and presented back to the user.
To assist in accuracy we will also be integrating our ADDRESSABLE product into PDFx. ADDRESSABLE has unmatched results in stitching third party data sets together and so for the Underwriting PoC mentioned above this will be incredibly beneficial to be able to pull data from multiple sources.
Interested in finding out more? Contact us →