
- Published on
Week 34 in review
- Authors

- Name
- Edwin Groenendaal
- @dharmatologist
In our second-ever Week in Review we will look at our current work in a bit more detail. It's been another busy week despite (or because of?) the Holiday period, with a combination of feature delivery work and foundation/prep activities.
For product context, see PDFx and ADDRESSABLE.

What did we do this week
PDFx
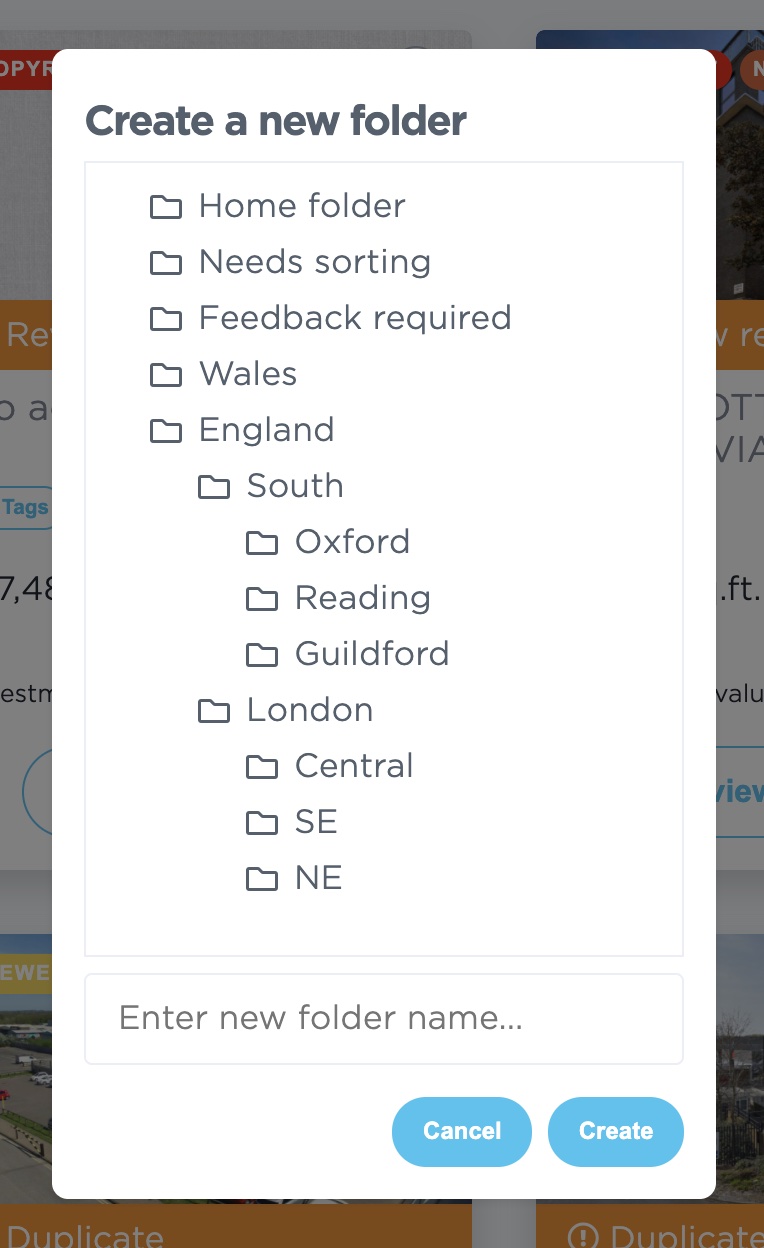
Folders in PDFx
The back-end work for folder support is complete, and the front-end work is nearly there, too. This week we've worked on a UI to create new folders. At the moment, we'll follow the well-trodden path of a parent folder selector and Folder Name box. Everyone loves a nice folder tree!
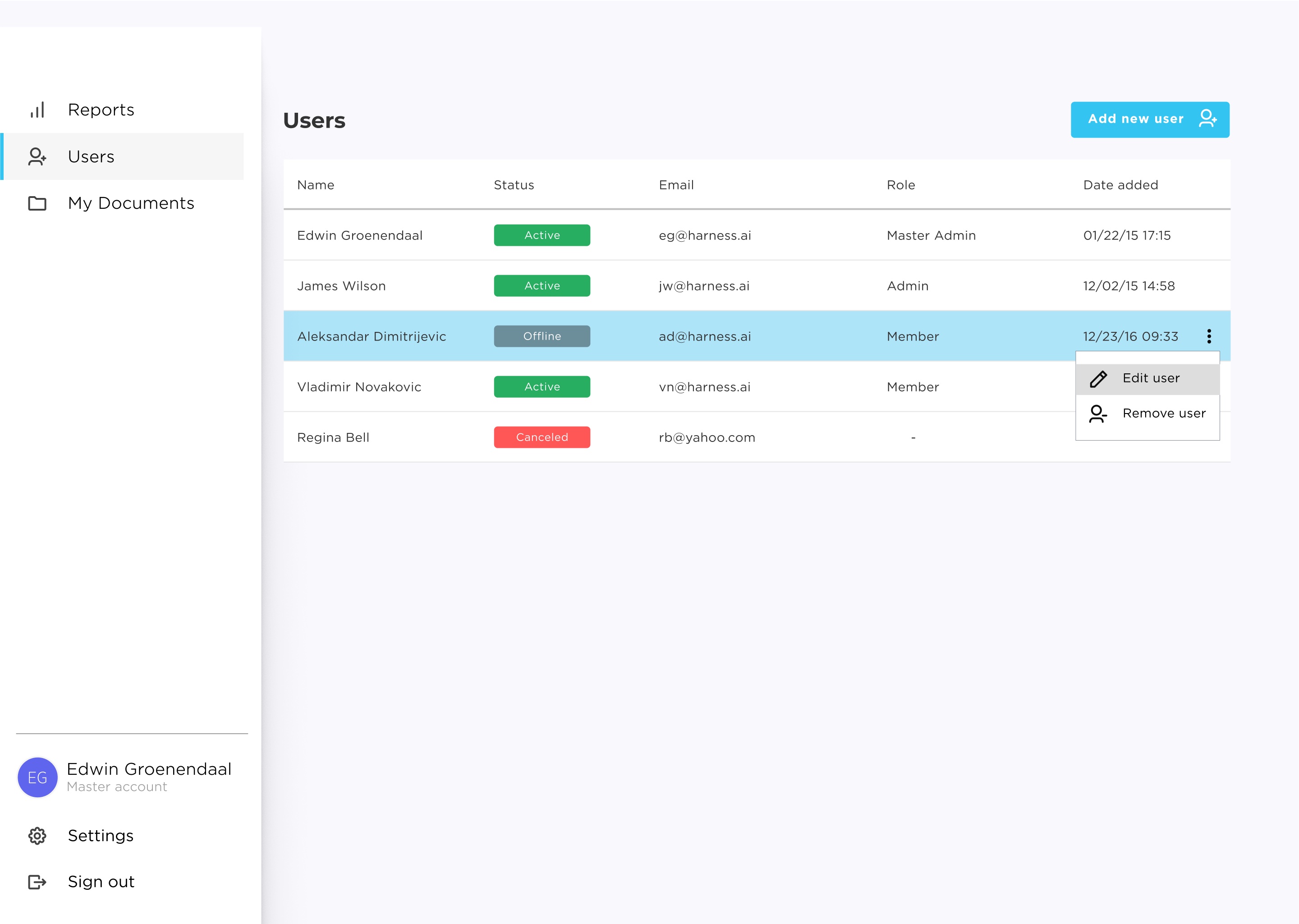
More work on admin app
We continue to work on the administration web app for PDFx. This week we created some of the CRUD endpoints on the back-end. The Azure Functions platform has come a long way since the first version and it's really easy to put together function apps that respond to triggers and deal with resources like queues and data stores for output or side effects.
'Soft' data formatting
In some ways, a Data Extraction tool is ironically a lot like a data entry tool. A good Data Entry application lowers the threshold for users - the aim is, after all, to get data in as quickly and easily as possible. To that end, a Data Entry application is typically tolerant of data typing. The ultimate example is Microsoft Excel, which allows free-form editing and attempts to figure out what the user intends to do, on the fly.
PDFx extracts data from PDF documents and it's got a good idea of what sort of data to expect - is it extracting a number, or currency, or maybe a date? However, there are lots of examples where data is usually represented as numbers, but not always. Common placeholders like 'POA' replace numbers, and sometimes custom explanatory text is a valuable data point in lieu of a number or date.
To cater for this, we added 'soft' data types to PDFx, and we're currently working on extending this to data extracted from tables, too. So that means we'll recognise a data type such as a number or currency, and format it as such. Or, leave a value alone if it doesn't conform.
That means we don't throw data away, and the user has the information they need to make decisions, without sacrificing UX and legibility.
ADDRESSABLE
Analytics endpoint and grouping
We're very excited to be working on the third 'leg' of the ADDRESSABLE interface: after the User Interface and the transactional REST API, we're now developing out the 'analytics' interface.
Basically this lets a user run map-reduce operations directly against our super-connected data set, without any need to ingest data into local databases or DaaS platforms. At the moment we're using an ECMAScript (JavaScript) interface, and in the future this will also be available through a GraphQL endpoint.
Basic MapReduce operations already work, and now we're adding the ability to group data by one of the many entities offered by ADDRESSABLE, such as Postcode areas or LandRegistry titles.
Our objective is to offer the full suite of data platform primitives - scanning, filtering, clustering, projection (mapping) and reduction.
We'll do a full blog article on the ADDRESSABLE analytics endpoint in the near future.
Interested in finding out more? Contact us →